Things About Scoliosis They Never Taught You
…because they did not look to find them and thus did not know them.
This is one of the best reasons you should buy the Advanced BioStructural Correction™ At-Home seminar and use it in your in your practice. By the way, x-ray is not needed in using ABC™ and you still still get the changes.
These are typical examples of layered curves and why most methods do not undo scolioses. The most basics of explanations is below the presented case study.
This is a 31 year old female patient. The radiographs below demonstrate progressive reduction of adult scoliosis with the method taught by Dr. Jutkowitz in Advanced BioStructural Correction™.
This case is presented by Dr. George Kukurin of Pittsburgh, PA. It is nothing special, just a typical patient. What is special is that George has never been to a live seminar teaching Advanced BioStructural Correction™ and has never met Dr. Jutkowitz or been taught by him or anyone else in person. You too can learn to do this from just the At-Home seminar.
This women was a patient in my office since 1997. She had chronic back and neck pain.
In Oct of 1999 we switched her from diversified/CBP/Pettibon to Advanced BioStructural Correction™.
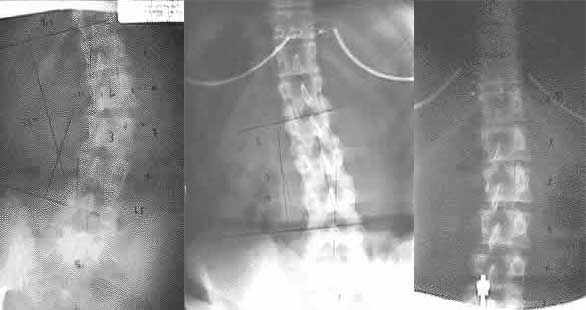
The films on the left were taken after several years of CMT and before we switched her to ABC™ . Note she has a scoliosis which measures 35 degrees by Cobb’s method. The scoliotic apex is at L2 and the distance from the spinous-laminar line to the lateral aspect of the vertebral body is 1.75 on the left and 4.5 on the right suggesting vertebral body rotation.
After a course of ABC™ treatment she was re-x rayed on 12/22/1999. Note the spine has transformed into a lateral translation with a small 6 degree scoliosis (Cobb’s method). This represents a 29 degree reduction in her scoliosis. The rotation of L2 did not change. (1.75-4.5)
The patient continued with ABC™ technique and was re-x rayed on 2/5/2001. Note the scoliosis has been eliminated, the lateral translation has been eliminated. The L2 rotation remained virtually unchanged at 2-4mm.
It is tempting to interpret the sp-laminar line / vertebral body measurements as indicating the patient has a structural scoliosis with asymmetrical pedicles. The right pedicle being substantially longer than the left which means it is a structural scoliosis with no change possible.
Dr. Kukurin
Additional comment by Dr. Jutkowitz:
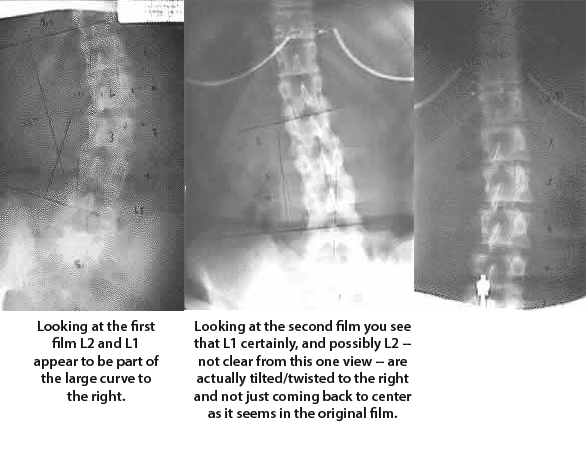
Looking at the original films you can just barely see that L5 does not lineup as part of that lateral curve to the right. It is almost like L4 and 5 are in a line and then there is a bit more of a bend at L3-4 suddenly sharper bend at L3-2. I would have to see and measure the laterals also to get exactly how many curves there are just from one set of films, but the follow-up films show a typical sequence of unwinding or untwisting layered curves.
When you see something like that flat spot in a curve (like at L4-5), you can bet large amounts there is an additional curve between the vertebrae involved in the flat spot. (It can be a short curve but a curve nonetheless.) The amount of mechanical stress in these curves that are pulled flat by compensations is just as important or, often, more important than the large obvious one. Without a technology of unwinding or untwisting these ENTIRE sets of curves there is no chance to “straighten” a scoliosis.
It is like when you twist a rubber band over and over until the twists start twisting on themselves into a double layered twist.
What is happening here is that the twists at L4-5 and L5-sacrum are being twisted even further by the large twist (to compensate) so they are pulled straight like a bent spring that straightens when it is stretched even though the twist is still there mechanically creating even greater stress on that area.
This is the reason treatment of scoliosis has been such a failure in chiropractic, osteopathy and even medicine. It is also the reasons for the severe reactions of patients who have their spine forced “straight” by surgery. When people have those reactions, as they do in most cases, they have not been straightened but wound up or twisted up more tightly.
With Advanced BioStructural Correction™ you are reducing the twist and the body unwinds or untwists like a big spring as seen in the above sequence of films. That is why doctors all over the world are so successful with more conditions than you might think using ABC™ get for your practice today. How to Learn ABC™.
In the case above there is more than one curve in that flat spot. There is a curve between L5 and the sacrum that remains unseen until you notice the way L5 does not go on the second film and the direction the spine takes starting at L5 in the last film. Once you know about it and what to look for you can see it on the first film. (That is why you need the laterals too; you can make a more complete determination on that first set when you have a full set of measurements in three dimensions. You can make a winning bet that L5 did not line-up smoothly with L4 on the lateral, though it may seem to on the first AP film.)
That curve to the right in the lower lumbars of the first films is actually three curves:
- L5 or so going right – not seen until the second and third film as discussed above.
- L4 going left – seen most obviously on the second film.
- L3 going left on L4 (which is seen more obviously in the curve of the second film as she improves and the body untwists to the left at that point — This is not seen obviously unless you know what to look for but would be on a film taken a short time after the second — which was not taken. It is not as obvious as the lowest curve to the right — L5 not going left but you can notice L3 does not lineup with L4 going left. It is a separate and additional curve.)
Note that the above is only a partial discussing of what is occurring on these films as it does not discuss the layered curves above the L3-L2 point.
Because they never had a technology that truly unwound the multiple layered curves (that is not redundant, I mean MULTIPLE layered curves) and never understood it when they did see it on x-ray, chiropractic as a profession has generally thought that a spine that looked fairly straight on an original AP film and looked more scoliotic on a second film 4 weeks later conflicted with the basic tenet that chiropractors were straightening the spinal column and getting people more well.
What they missed was that the spinal column needed to be viewed as a whole in three dimensions and in multiple positions (multiple mechanical stress patterns) to see how it changes under different mechanical stresses as it unwinds its twists and bends. Only viewing and measuring the spinal column in three dimensions can you truly determine if you are improving its mechanics or not. This is easily done using standard full spine (14×36) films in the AP and Lateral projections with the patient relaxed in the sitting and standing positions.
The largest clue is noticing curves versus flat spots in the spinal column on either the lateral or the AP film.
Nice job GW.
For those of you having the question: This really is a typical result and many other docs report the same. It demonstrates and illustrates an unwinding or untwisting curve in its typical appearance. The fact that the curve to the right is LAYERED is missed by many. Trying to straighten this as one curve does not work and causes many docs and patients great anxiety because what they are doing does not work to untwist all the curves — therefore they do not change the scoliosis.
Dr. Strauss asks how you predict the changes.
Dr. Strauss,
The way to predict the changes is included in the discussion on above (“When you see something like that you can bet large amounts that there is a curve between L4 and L5 (a short one but a curve none-the-less) that is just as important or more important than the large obvious one. and In this case there is also one between L5 and the sacrum that remains unseen until the last film — unless you know what to look for.”)
To predict exactly what will happen at a given point you need to measure the angles on the AP, on the lateral and the axial spinal length of the segment of the curve involved (on George’s line) vs. the spinal length overall and their ratios to what people of that height typically have when other measurements approach a balanced ration (not a pathological balance).
It becomes even easier if you have standing and sitting films with those measurements made on each. In that case the changes occurring from position to position and their ratios can even give you a prediction of the order in which they will release.
The predictability is based on the vectors (remember direction AND magnitude) of force required to hold these curves in those positions. Remember that those vectors are torque, spiral and stretch along the axis of the spine as well as right-left and a-p.
The basic is that you can ask the question: This vertebra is stuck forward and– (the and can be any other direction except posterior), if I bring it posterior enough so it works properly in the lever system of the spine, what else will the body change?
That what else will depend upon what is occurring elsewhere in the spinal column or even possibly the legs, pelvis or head. In cases of certain types of injury it can even depend upon what is occurring in the arms.
For more data take a look at some of the other scolioses on Dr. Kukurin’s web site.
Even though you only have the AP in the pre, you can still see that L4-5 do not curve with the rest of the scoliosis to the right and that L5 goes right on the sacrum while L4 goes left on L5. In the second film you can see that start to show up.
As far as I know there were no sitting and standing and no full spines so what you have is a lack of the rest of the data needed to make accurate predictions for what will happen in the rest of the curve because in the second pic L3 and 2 are straight in the curve which means there is at least two more curves inside that original large curve to the right.
Hope this answers enough of your question Joe.
The two main points are that if you are truly correcting subluxations you will most certainly get all the changes in structure people are talking about ALONG WITH the changes in neurological tissues and response.
The other is that the thing to work on AND THE ONLY THINGS TO WORK ON are the things the body cannot self-correct and not the things the body can self-correct but does not.